
A Hardware Guide to Running AI Locally at the Industrial Edge

As artificial intelligence (AI) continues to reshape industries, the focus has shifted from centralized cloud processing to real-time decision-making at the edge. For system integrators, this shift isn't just about performance: it’s about enabling smarter, faster, and more autonomous operations where decisions need to happen instantly and securely.
But running AI “at the edge” can mean very different things depending on the architecture. Some deployments involve AI models embedded directly into devices like industrial PCs or smart cameras, while others rely on on-premise edge servers that sit within a facility’s data infrastructure.
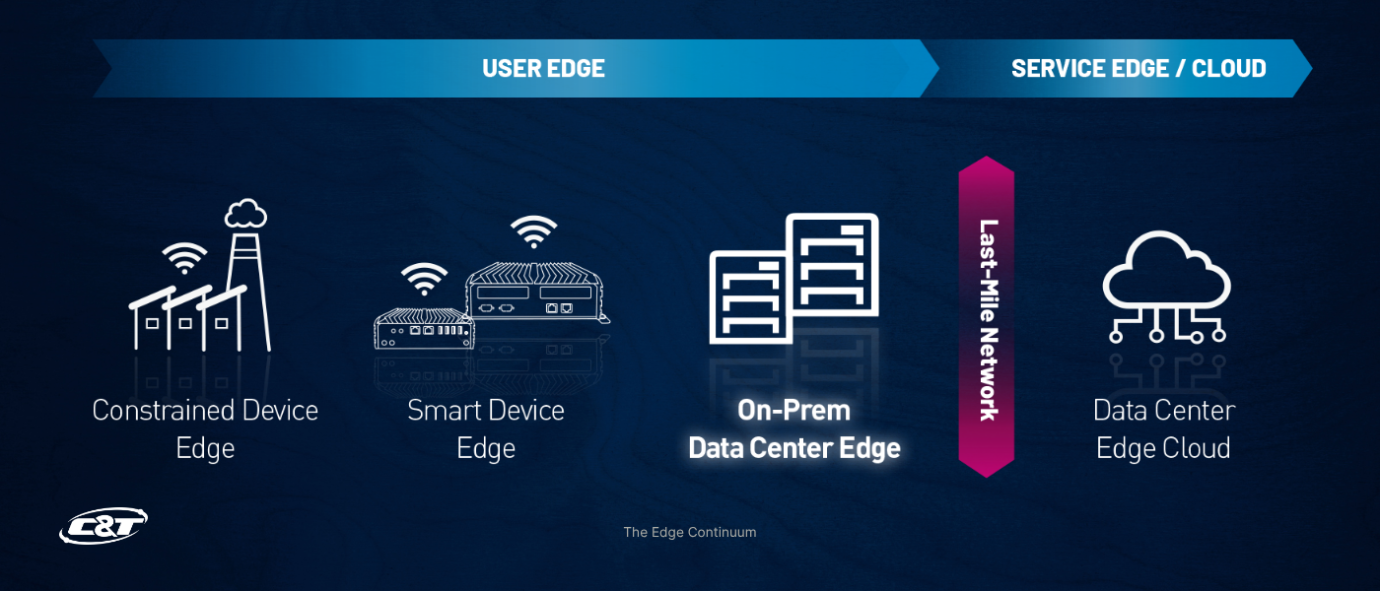
In this blog, we break down the two key approaches to local AI deployment: Smart Device Edge and On-Prem Data Center Edge. Explore how to select the right strategy for your use case. Whether you're building an autonomous robot, a vision inspection system, or a private AI assistant powered by LLMs, understanding the edge landscape is crucial to successful AI integration.
Why Run AI Locally?
Running AI workloads locally at the edge, instead of sending data to the cloud, unlocks major advantages, especially for mission-critical, latency-sensitive, and privacy-aware applications. For system integrators, local AI enables faster decision-making, greater control over data, and lower long-term operational costs.
- Real-Time Response
Local inference removes cloud latency, enabling immediate decisions for tasks like robotics, inspection, or safety alerts. - Lower Bandwidth and Costs
Processing data on-site reduces the need to transmit large sensor or video files, saving bandwidth and minimizing cloud expenses. - Enhanced Data Privacy
Sensitive data stays on-prem, helping meet regulatory requirements and internal data control policies. - Offline Operation
In remote or mobile environments, edge AI ensures systems stay functional even without internet access. - Scalable Architecture
Whether scaling with embedded devices or edge servers, integrators can tailor deployments to specific workloads and environments.
In short, local AI brings intelligence closer to the action — faster, safer, and more efficiently.
Two Types of Local Edge AI Deployment
Not all edge AI deployments are the same. For system integrators, choosing between a smart device edge and an on-prem data center edge depends on the workload, environment, and performance needs. Both run AI locally, but their architectures and roles differ significantly.
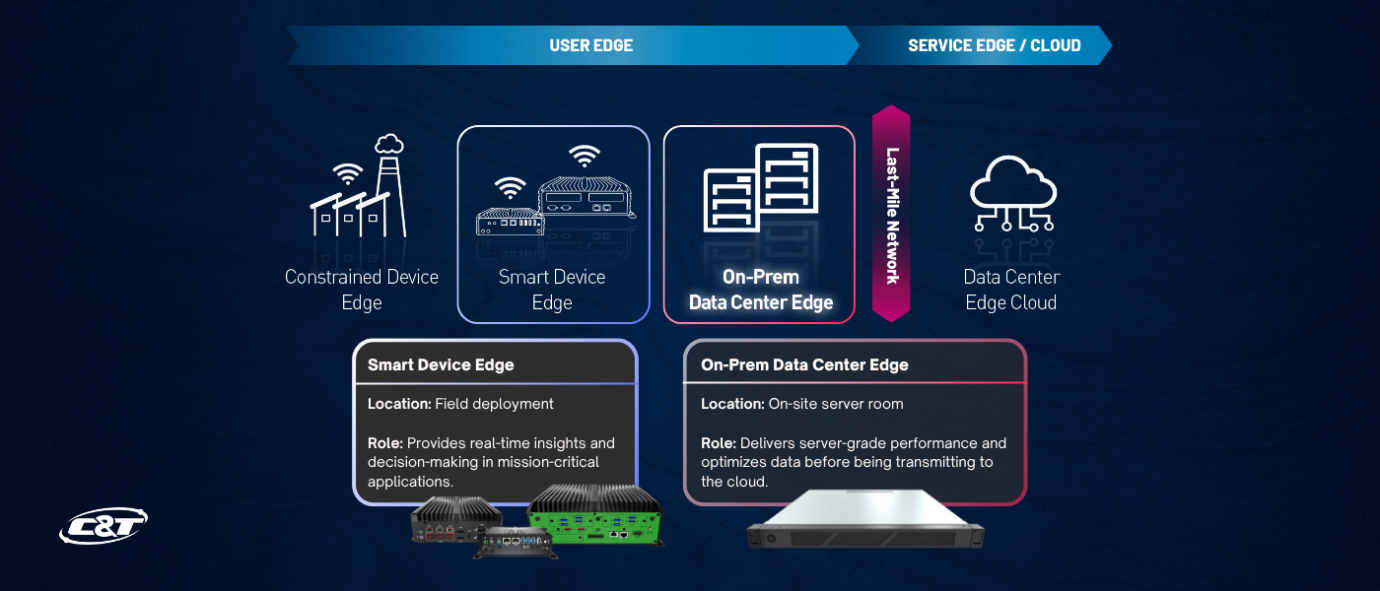
1. Smart Device Edge
AI runs directly on distributed embedded systems or industrial devices located close to sensors and actuators. These compact, rugged platforms power real-time insights for machinery, enabling tasks like object detection, motion tracking, and anomaly detection to happen instantly at the source.
Typical Hardware:
Fanless industrial PCs with NVIDIA Jetson Orin, x86 CPUs, or M.2 AI accelerators (e.g., Hailo)
Use Cases:
AGVs/AMRs, traffic cameras, factory machine vision, surveillance systems
Key Advantages:
- Ultra-low latency near the data source
- Lower power consumption
- Rugged and scalable for distributed environments
- Ideal for real-time detection and autonomous behavior
2. On-Prem Data Center Edge
AI runs on centralized server-class systems installed within the facility but outside the cloud. Unlike smart device edge, these systems aren’t embedded into machinery or vehicles — instead, they operate as a centralized processing layer that aggregates data from multiple edge devices. With higher compute power, they handle tasks like LLM inference, cross-facility analytics, and decision orchestration. Often serving as the final layer before data reaches the cloud, on-prem edge servers ensure secure, high-performance AI while maintaining local control.
Typical Hardware:
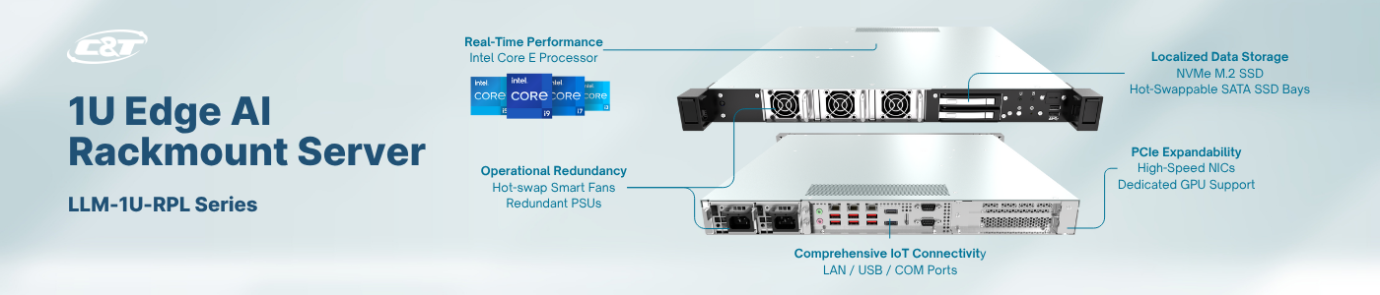
Rackmount edge servers with high-performance GPUs (e.g., LLM-1U-RPL Series 1U Edge AI Rackmount Server)
Use Cases:
Local LLM inference, facility-wide analytics, video processing aggregation, private AI agents
Key Advantages:
- More compute power for larger AI/LLM models
- Serves multiple endpoints or devices
- Maintains data locality for secure AI processing
- Suitable for hybrid workflows (model training, analytics, agent interaction)
Choosing the Right Architecture
Selecting between smart device edge and on-prem data center edge depends on several practical factors — from compute requirements to deployment scale. Here's how to determine the right fit for your project:| Criteria | Smart Device Edge | On-Prem Data Center Edge |
|---|---|---|
| Deployment Scale | Distributed (per machine, per sensor) | Centralized (per facility, control room) |
| Compute Power | Moderate (e.g., INT8 models, Jetson Orin, M.2 AI modules) | High (e.g., INT4/FP16 LLMs on RTX or L40S GPUs) |
| Inference Tasks | Object detection, motion tracking, edge analytics | LLM inference, video aggregation, private AI agents |
| Data Sensitivity | Keeps data local to device | Keeps data within the premises but processes centrally |
| Latency Requirements | Ultra-low (<30ms) for local sensor fusion and actuation | Sub-second for complex reasoning or response generation |
| Hardware Footprint | Small, fanless, ruggedized | Rackmount, actively cooled, more power-hungry |
| Scalability | Add more devices as needed | Scale up with GPU upgrades or add more server nodes |
🔧 Tech Tip:
Combine both architectures where needed. Use smart device edge for real-time tasks at the edge of the network, and an on-prem edge server to process, analyze, or summarize aggregated data — especially when deploying LLMs or private AI assistants.
Real-World Use Cases
To better understand how smart device edge and on-prem edge servers work in real scenarios, let’s look at two examples:Smart Device Edge: Vision-Based Obstacle Avoidance for AGVs
Scenario: AGVs in a warehouse need to detect and avoid obstacles in real time.

Solution:
- Hardware: Mid-Range Edge AI Computer with NVIDIA Jetson Orin Nano/NX (JCO-3000-ORN Series)

- Integration: Cameras capture visual data, processed instantly on-device
- <30ms inference latency
- No reliance on external networks
- Reliable, autonomous operation in dynamic environments
On-Prem Data Center Edge: Private AI Agents for Factory Operations
Scenario: A manufacturing facility deploys an on-site AI agent to help engineers access standard operating procedures, troubleshoot issues, and answer internal queries, all without relying on the cloud.

Solution:
- Hardware: LLM-1U-RPL Series with RTX 4000 SFF Ada GPU
- Model: Quantized Llama 3.2 11B running locally
- Sub-second response time for natural language queries
- No external data transmission; full data sovereignty
- Enables real-time knowledge retrieval and AI-driven support on the factory floor
Conclusion
Running AI at the industrial edge isn’t a one-size-fits-all approach: it’s a matter of selecting the right hardware, deployment architecture, and integration strategy to meet specific application needs. Smart device edge delivers fast, localized intelligence where the data is generated, ideal for real-time decision-making in machines, robots, and vision systems. On-prem data center edge provides the compute muscle for centralized tasks like video analytics, LLM inference, and facility-wide coordination, all while keeping data within operational boundaries.
For system integrators, the key is to align AI workloads with the appropriate edge tier, considering performance, scalability, and environmental demands. In many cases, the most effective deployments combine both approaches, enabling distributed intelligence at the edge with centralized compute to orchestrate and optimize it.
By understanding and leveraging both ends of the industrial edge spectrum, integrators can build future-ready AI systems that are responsive, secure, and built to withstand real-world industrial challenges.
If you have any additional questions, feel free to contact our rugged tech experts. We're here to help you move your AI projects forward.