
How Edge Servers Are Powering On-Prem LLMs at the Industrial Edge

As artificial intelligence advances, the way we design and deploy infrastructure is evolving in real time. Enterprises are no longer relying solely on cloud-based platforms. Instead, many are bringing AI capabilities directly on-site with on-prem LLM deployments, unlocking new levels of performance, control, and responsiveness at the edge.
At the heart of this shift is a new class of edge servers—purpose-built to run large language models (LLMs) and generative AI workloads on-premises. But to understand the significance of this evolution, we first need to examine the broader market trends fueling it.
The AI Shift: Edge and Generative AI Are Moving On-Prem
According to Gartner’s Hype Cycle for Artificial Intelligence, Edge AI and Generative AI are both progressing rapidly toward the plateau of productivity. While Edge AI is forecasted to reach maturity in less than two years, Generative AI is expected to follow closely behind within five.
This trend signals a fundamental shift: AI is moving out of the research lab and into operational deployment. And increasingly, that deployment is happening on-prem, closer to the physical environments where data is generated and decisions are made.
Understanding the User Edge: Where On-Prem LLMs Operate
At C&T Solution , we define the edge as a layered continuum, especially within what we call the user edge. This includes two key layers:
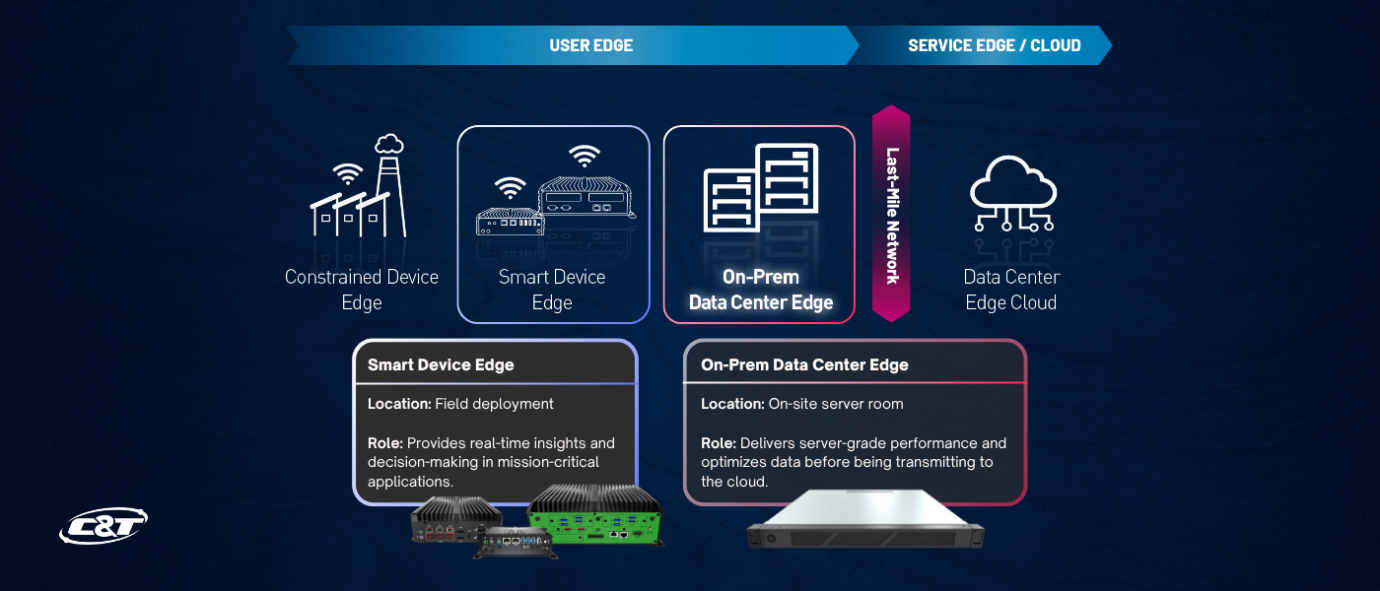
1. Smart Device Edge
This layer consists of rugged, embedded computing systems—such as C&T’s RCO, BCO, and JCO Series—installed directly in machines, vehicles, or production lines. These systems perform real-time inferencing and data processing close to sensors and actuators.
2. On-Prem Data Center Edge
This is where on-prem LLMs come into play. Located in localized server rooms or micro data centers, this layer features scalable edge server infrastructure designed to handle more compute-intensive AI workloads while ensuring data remains secure and on-site.
Edge servers at this layer bridge the performance gap between embedded computing and centralized cloud environments—delivering the horsepower needed for AI without sacrificing latency or control.
Why On-Prem LLM Deployments Are on the Rise
Deploying large language models on-premises offers several compelling advantages:
- Reduced Latency: On-prem LLMs process data in real time without the delay of sending it to the cloud.
- Data Sovereignty: Sensitive data remains within the local environment, supporting regulatory compliance and internal governance policies.
- Cost Efficiency: By reducing cloud dependencies and bandwidth usage, enterprises can better control operational expenses.
- Resilience: AI applications continue to operate even if external connectivity is lost.
These benefits make on-premise deployments not just viable—but essential—for industrial applications in manufacturing, logistics, energy, and beyond.
How Edge Servers Enable On-Prem LLM Inference
The edge server plays a critical role in making on-prem LLM deployment feasible. It consolidates several core technologies needed for generative AI:- Real-Time AI Processing: High-performance CPUs and GPUs deliver the compute power necessary for local LLM inference.
- Robust Storage: NVMe SSDs ensure fast access to training data, models, and inferencing output.
- I/O-Rich Interfaces: Support for industrial IoT protocols and connectors enables seamless data ingestion from cameras, sensors, and controllers.
- Hardware-Level Security: Features like secure boot, TPM modules, and locked BIOS settings harden the server against cyber threats.
- High Availability: Redundant fans and power supplies ensure 24/7 reliability in mission-critical applications.
C&T Solution’s LLM-1U-RPL Series: Purpose-Built for On-Prem LLM Deployments
To address the growing demand for on-prem LLM infrastructure, C&T developed the LLM-1U-RPL Series—a compact yet powerful 1U edge server designed for Industry 4.0 environments.Key Features:
- Short-Depth 1U Form Factor: Fits into tight IT spaces and wall-mount enclosures in edge deployments.
- High-Performance Processing: Supports enterprise-grade CPUs and optional GPUs for accelerated AI inference.
- Scalable Storage: Up to four NVMe drives for high-speed local data access.
- Flexible PCIe Expansion: Accommodates AI acceleration cards, NICs, and additional I/O modules.
- Industrial Reliability: Engineered with hot-swappable fans and redundant power to ensure continuous uptime.
This edge server delivers the balance of compute density, ruggedization, and connectivity that enterprises need to deploy LLMs on-prem without compromising performance or security.
The Future of AI Is Local
As AI models grow more complex and data volumes continue to surge, pushing processing closer to the source is becoming a necessity. On-prem LLM deployments are unlocking the full potential of generative AI—offering faster, more secure, and more reliable insights at the edge.C&T Solution’s LLM Series represents a scalable, future-ready platform that empowers enterprises to move AI workloads out of the cloud and into the environments where they matter most.
If you have any additional questions, feel free to contact our rugged tech experts. We're here to help you move your AI projects forward.